
Since the time humans started to store records electronically they were always looking for the most efficient way of storing and retrieving those records. Then came the era of data processing and Frank Todd published his iconic “ A relational model for Data for large shared data banks”. That gave birth to the datastore phenomenon called Relational Database Management Systems (RDBMS). That became the gold standard for most companies in how they stored and processed their data. To store and process the data in RDBMS we needed a universal language and in 1970 Raymond Boyce and Don Chamberlin came up with a a language SEQUEL which became popular in its abbreviated form SQL. so SQL databases ruled the roost for almost 4 decades. Which meant we created a structure to store our data and then divvied up data into different objects called tables and then built relations between these tables. So the pre-requisite for this kind of data storage and retrieval was that the data had to be structured. Before the data was stored the schema had to be built.
But with the volume and velocity of data exploding over the years and the advent of huge volumes of unstructured data with proliferation of social data platforms and blogs the data was no longer in structured form. So the scaling because of volume and velocity and advent of huge amount of unstructured data RDBMS platform was no longer the de facto solution and we saw the proliferation of data stores which no longer adhered to RDBMS principles and we popularly known as NoSQL databases.
These databases do not adhere to any predefined structure and data could be stored in the form as they arrived instead of divvying them up in a predefined tables with relationships. Most popular being JSON (JavaScript Object Notation) documents. These datastore can be created in a very agile fashion as they do not need an in depth data discovery and minute data structure. RDBMS scaling is not very cost effective while in NOSQL databases scaling is easy and a great ROI.
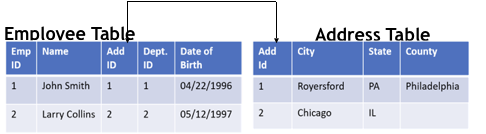
Here is an example of how data is stored in RDBMS & NOSQL datastore:
RDBMS:
JSON:
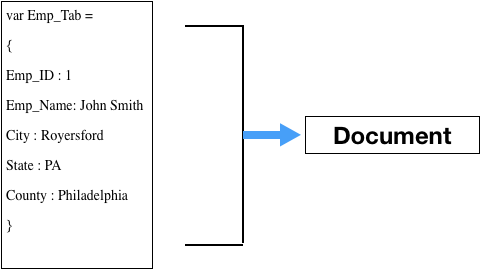
var Emp_Tab =
{
Emp_ID : 1
Emp_Name: “John Smith”
City : “Royersford”
State : “PA”
County : “Philadelphia”
}
{
Emp_ID : 2
Emp_Name: “Larry Collins”
City : “Chicago”
State : “IL”
Food : “Pizza”
}
So in the above example you see the Employee information is stored in a defined schema consisting of 2 tables called Employee and address and a cardinal relationship exists between these 2 tables. Each entry of an employee is stored as a record and the information has adhere to the defined structure and cannot be flexible.
But in the second case the information is kept in a JSON document structure and does not adhere to a predefined schema. If you look closely the information details differ in the JSON documents and yet they can be stored which not possible in a predefined schema.
Secondly, to get the entire employee information in the SQL structure I have to join the two tables to extract the entire information and sometimes these joins can be very costly as it might require joining many very large tables and complex join algorithms. But in the case of NoSQL the data is stored in one place and retrieving that information is much easier with no costly joins. Though this can be advantageous for bulk reads and writes but proves to be pain when you want to compare and establish relationship between documents.
Relational data stores scale vertically but NoSQL data stores scale horizontally so scaling for NoSQL is much easier and less expensive, also database sharding can be implemented much better in NoSQL data stores which makes the distribution of workloads much easier and simpler.So if you are collecting petrabytes of data consisting of unstructured social media feeds and going to do so statistical analysis on the collected data it would be very easy to implement in a NoSQL data store.
RDBMS are optimized for transactional systems where you have to perform lots of updates, inserts and deletes and for this you need some data consistencies. RDBMS systems provide you with ACID (Atomicity Consistency Isolation Durability) property which is very essential for critical transactional systems but very hard to achieve in NoSQL system
Now let’s put our solution architect hat on and see when looking at some use cases where you adopt each of these technologies
- For all the talk about “schema-less” data which is unstructured is still very small percentage compared to structured data which we analyze or transact in real life. Real life inventory, accounting , personnel, manufacturing, sales data is still very structured and predictable. For every application which requires crawling through social media feeds, web server logs, blog posts there are thousands of applications which manage employee details, inventory, book keeping transactions etc. This real world data is finite and grows in predictable numbers.( Not every corporation has Google Data Deluge)
- In real world you need to join information sets to and query the data to make meaningful decisions and that can be done more easily with a Relational database.
- Most transactional systems need ACID consistency .
- Arguing that RBMS does not allow you rapid development is like saying my hammer could not build the house because it does not have the blueprint. A powerful tool needs a direction
On the flip side the advantages of NoSQL systems are DevOPS related
- A well made NoSQL solution will handle massive writes better than RDBMS. I am talking about a magnitude of 300k / second
- When you store that much amount of data you have to read/analyze and answer tactical questions. A NoSQL solution is read optimized which can handle triple digits petrabyte of data reads
- Traversing graph networks consisting of terabyte of data is not easy with RDBMS solution
- Storing unstructured data like web pages, messy lot files, emails, social media feeds is very difficult to store in a RDBMS schema and also difficult to scale.
So coming from a banking background I will give you this simple example.
Your banking has business domains like product, party, accounts, transactional systems, GDPR, FRAUD detection, HR, CAPEX &OPEX, Contact Management &Marketing etc will always have defined and predictable data and will involved a lot of CRUD (Create Read Update Delete) So it’s easier to put them in a defined schema and perform these operations. The percentage increase of data can be predicted and appropriate scaling can be pre planned. So in most such cases you RDBMS is up to the task. On the other hand your bank launches different financial products and they want to listen to the social media feeds if your product hashtag is trending or what people are saying about your products. For this you need to capture all sorts of unstructured social media feeds blog posts etc. This data mostly consists of capturing such feed and not much operations on deleting or updating such data. You just need to read the data and analyze it and NoSQL datastore are optimized for such operations. The volume and velocity of such data in high and unpredictable. So your solution is NoSQL or document based data stores.
As you can see from the above example that you have to choose the tool based on the task. You cannot use an axe to chop your onions neither can you use your chopping knife to cut down a tree. Both these data stores can co exist and twain shall meet sometimes in data lake . That in another blog post.
