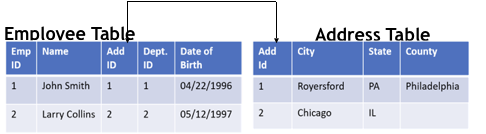
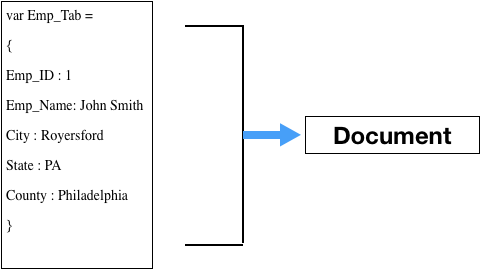
Amlan Dasgupta
What is Distributed Caching
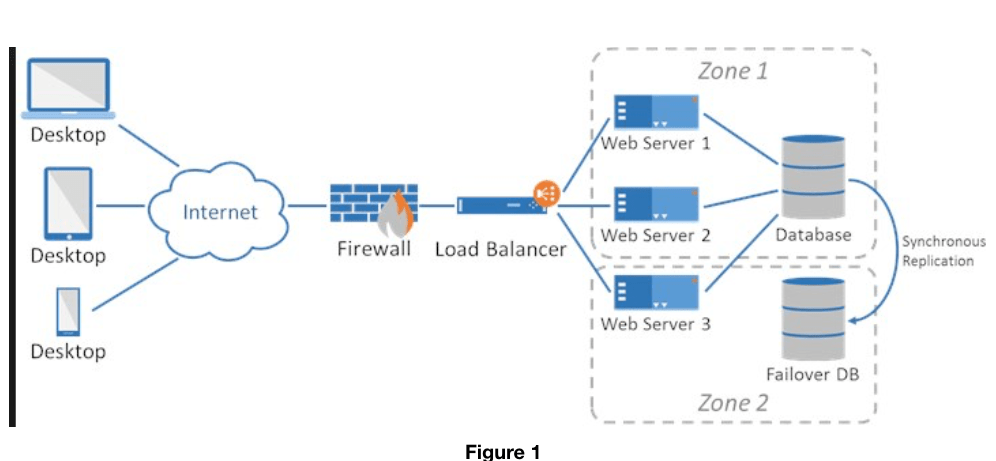
A simple application network architecture looks something like this:
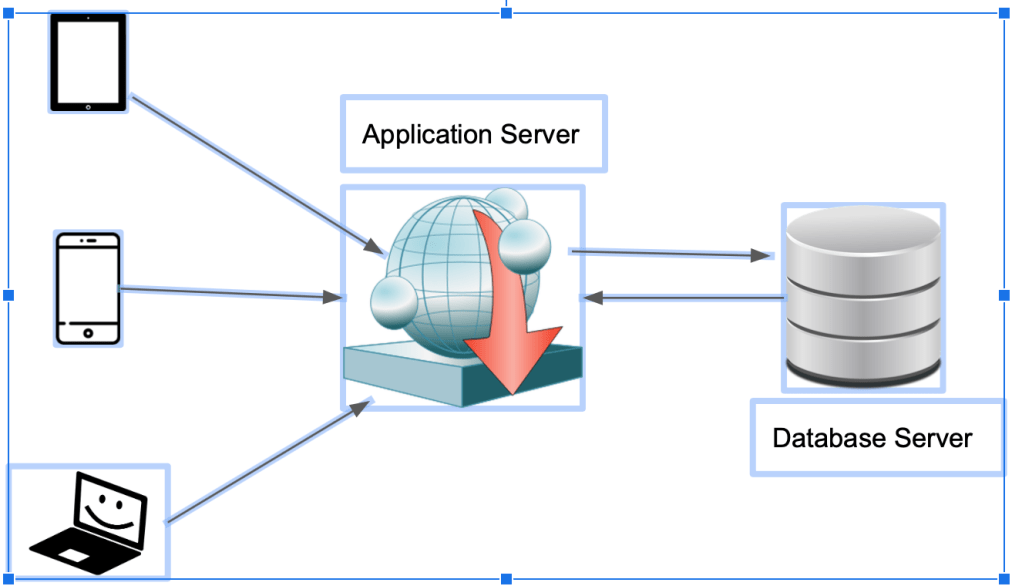
There are user hitting the application server with data requests. The app server in turn hits the database server with those requests and then processes the results to put out those user requests. In this scenario when number of users increase so does the network calls to the db server thus increasing traffic and I/O time. Also computational requests increases which proves to be costly over a period of time.
So to resolve this we use Memory Cache. Below is a simplified architecture for the same:
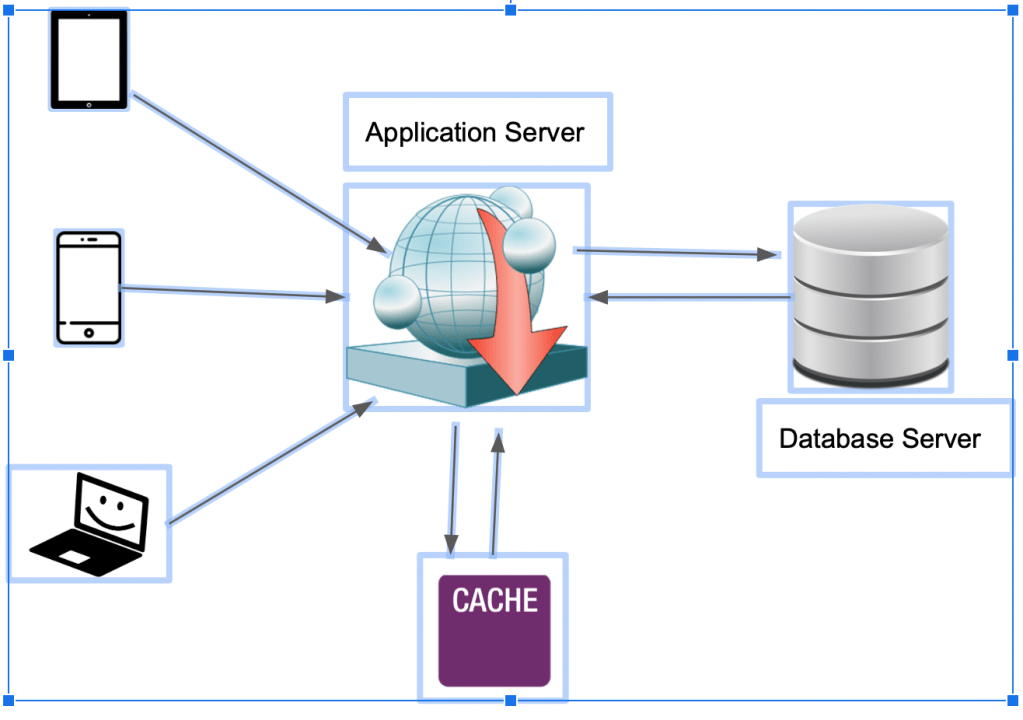
The first use case is that you get lot of requests to for profile information for a certain set of users resulting in a lot of network calls. In this case you save it in a memory cache with a key pair value and get the profile information directly from the memory cache thus reducing network calls.
The second use case is that you get a lot of common computational requests like quantity of products sold by region. That can prove very costly if you go to the db get different products and group them by region and compute the the totals every time a request comes in. What you can do it is do it once and store the result as a key pair value in the cache and return the results from cache every time a similar request comes in. Thus avoiding network calls and repetitive computations
The third use case if there are lots of application servers hitting the same db server, the load on the db server increases. In that case you can create a distributed cache where you store different result sets and go fetch it from the appropriate cache and reduce load on the db server. But you have to be very careful here because cost of memory cache is costlier than commodity hardware so a thorough cost benefit analysis has to be done I.e. does speed of response outweighs the cost.
Also you cannot store infinite data in your cache as that proves to be counterproductive. You can only store a subset of the data from your database. So you have to have policies of what to store in your cache and when to evict data from your cache. So here are some popular Cache Policies:
- Least Recently Used: You create a queue of recently used values like, used in the last 5 seconds/minutes/hours and bump off the bottom of the queue entry when you add a new one. In this way you store the most recent and frequent data values and discard the oldest and least used data
- Least Frequently Used: This is a type of cache algorithm that manages computer the cache by keeping track of the number of times a block is referenced in the memory and purging the one with the least referencing frequency, once the cache is full and needs more memory.
- Sliding Window Policy:A sliding window policy maintains a queue of a specified size, into which entities flow. When the queue is full and a new entity arrives, the oldest entity in the queue is removed from the window (FIFO).
It is very important to have the right eviction policy in your memory cache. Some of the problems you might face are as follows:
- Extra Call: Bad eviction policy the purpose of having a memory cache is defeated if for every request you have to go back to the data store to service that call. Which means you are making that extra call and you are not getting any benefit for the cost incurred
- Thrashing: This occurs when you have a small cache. Leading to constantly loading and evicting entries without ever using the results
- Data consistency: When a server makes an update on a record which is already in the cache the changes are not reflected in the cache entry unless the record id evicted and reloaded again
Now the question arises where do you place the cache – A) Near the servers or B) Near the database
- Near the server makes results faster, but it eats up a huge chunk of memory for the app services resulting in app performance lag. It can lead to data inconsistencies between different server caches/ Most important if any app server goes down it takes the caches data to the graveyard
- Second option is implementing a global cache near the server using caching tools like Redis. Where you can scale up and down the memory. Data is more consistent. The cache is managed and less chances of failure. Only drawback is the data arrival is a little late which is very negligible
My personal choice would be option B. This allows for data replication which reduces a memory segment goes down and also helps in data consistency. Tenancy rules can also implemented at an enterprise level.
Lastly how to keep the cache and database values consistent. There are 2 methods to it:
- Write Through Cache: When there is an update to a record first check the cache for the record in the cache. If there is update that record and then go ahead and update the database for the same record
- Write Back Cache: If there is an update to a record go do it first in the database. Then check cache if it exists. If found write back the same updates in the cache.
These two methods will keep your cache and database consistent.